Blog
Charity sector data strategy and innovation with Elasticsearch
When I started at SCVO three years ago, we maintained a wide portfolio of websites developed in different languages and technology stacks, including WordPress, bespoke ASP.NET, and PHP/MySQL. We also had a strategic direction to move all business data from separate databases into Salesforce CRM. And I was tasked with managing the maintenance and development of our public web properties.
Improving the search experience
The first thing we needed was to take stock of our services and requirements. This included numerous standalone websites that had been created because the main corporate site wasn't suitable to house them at the time, as well as a major recruitment website, Goodmoves (that sent out tens of thousands of weekly digest email alerts matching user search preferences). One of the main complaints about the sites at the time was the search facilities on each of them. They were fairly inaccurate, and a common refrain was that you'd have more luck with Google than using the search boxes on our sites.
Early in our technical solution investigation, we decided on building around Elasticsearch. Although we didn't have any experience with it at the time (the closest I had previously used was Apache Solr), we saw there was a highly active user base, ongoing development, and a well documented and featureful query language. Additionally, the core of our new technology platform was to use Elasticsearch as a data store, not only for search results but also for most individual content pages.
We aim to eventually have all our services on this single technology stack, with public content held as Elasticsearch
documents and accessed via a number of websites that can access any/all content as required. This will allow the
main SCVO website to search for content across all our other websites, and for Goodmoves to show our training
courses, TFN news posts, and posts by organisations, as well as many other use cases. We're continually
improving our services thanks to Elasticsearch functionality — from finding "similar" content with
a more_like_this query, to searching against geojson region shapes with
a geo_shape query.
Moving to Elasticsearch Service
We looked into self-hosting an Elasticsearch cluster. But with a very small development team, we felt our time was better spent on the front-end development of our services rather than admin. Elasticsearch Service on Elastic Cloud has been a good fit for our needs, and it has proven highly reliable and easy to administer. Plus, with the premium features included with Elasticsearch Service, we've also recently started using Kibana on Elasticsearch Service to monitor and maintain our content.
The two main pieces of bespoke technical development were the indexer and the router. The indexer is the method we use to ingest content from Salesforce/WordPress/RSS/APIs and is a node app running on Heroku. The router processes HTTP requests, runs a number of tasks including Elasticsearch queries, and renders a page of content (or json, or email, etc.)
We use the Handlebars semantic templating engine not only to render HTML templates but also to programmatically generate Elasticsearch queries and/or further tasks based on earlier task results. Our router has been published as an open source project.
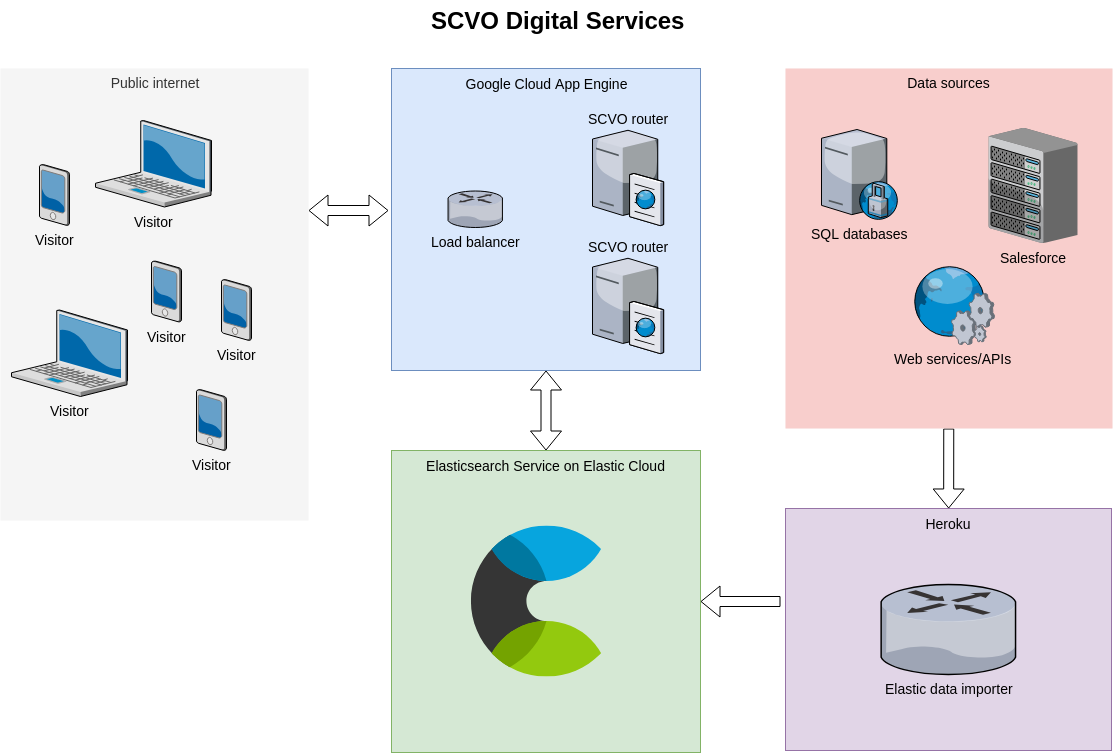
With these tools, most of the work in developing a new service is now in setting up page templates and queries around defined routes, as well as styling the resulting pages. This means we can spend more time focussing on UX details and improving search queries than the nuts and bolts of using/maintaining a PHP stack or JS framework. We often find ourselves offloading complex data processing onto Elasticsearch for things like term aggregations and complex geographical searches.
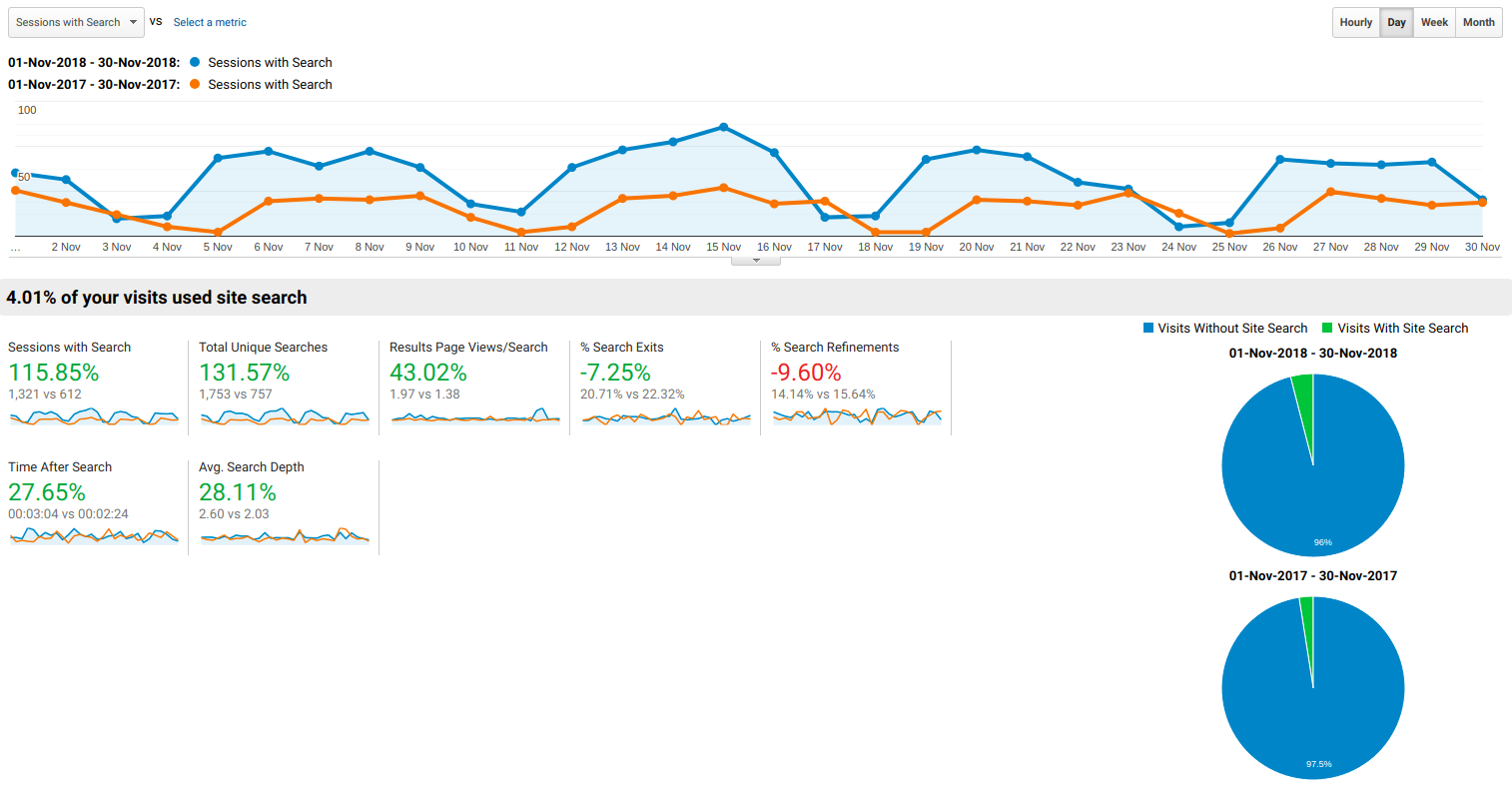
In terms of measuring impact, the primary aim of this work has been to improve the search relevancy of our content. Our users include charity workers looking for advice on running an organisation, people looking for a new job in the third sector setting up email alerts to match their search preferences, and policy workers/officials finding out more about the sector and sharing our research (this is not an exhaustive list... we're a big organisation!) The following screenshot from Google Analytics illustrates how much more site search is being used, which leads to a lower bounce rate and greater engagement with content.
We’ve even seen the following feedback: "It's now very easy to refine the job search as you go.[...] But my favourite
new feature has to be the Similar Jobs tab that's generated when you click through to
read about a job in more detail. It's by far the most useful tool on the entire site and makes the search a lot
easier, plus often more fruitful."
Conclusions and next steps
Elasticsearch has made the development and refinement of complex search relevance exceptionally easy, and we're
looking forward to upgrading to the next version for new features. One of our main future development tasks is
use the join datatype, a special field that creates parent/child relation within documents of the same index. We have a number of situations where we show information about an organisation that some content belongs to. At the moment, this is simply handled by separate content types where there is a unique ID of the organisation on the child record but could be more efficient if it were indexed correctly as parent-child.
Setting these things up early in the process saves a lot of time later, as you can't change field mappings once there is content in your index. We also plan to do a thorough test of our Disaster Recovery process — a full rebuild of our Elasticsearch cluster. Our indexer should easily handle the tens of thousands of documents within an hour, but it would be useful to fully document the process so it's straightforward in an emergency.
Finally, we're keen to further develop our router, as it's currently undocumented but feature-rich and performant. We feel that it's the best possible way to build a fully-fledged website directly on top of Elasticsearch documents.
If you’re interested in seeing our Elasticsearch implementation in use, check out our major services currently using this system: this website, Goodmoves, and Volunteer Scotland Search.
This blog post was also published as a guest blog with Elastic.